
Chilecompra: Algunas lecciones de un apagón
Una vez que pase la tormenta y se restablezca la normalidad, hay una oportunidad de aprendizaje para gestionar servicios de misión crítica y poder preparar mejor las situaciones de contingencia que deban enfrentar
Hace unos días celebrábamos los 20 años del Chilecompra, y pocos días después este servicio sufrió el peor apagón de servicios de su historia, y por lo que aparecen en las redes sociales, aún mantiene interrupciones e inestabilidades, y es probable que eso se mantenga durante algún tiempo.
Desde la madrugada del 12 de septiembre y hasta la noche del 19 del mismo mes, esto es, casi 7 días sin servicio, lo cual para un servicio de misión crítica como este es de la máxima gravedad.
El apagón
El apagón fue producto de un ataque del tipo ransomware sufrido por la empresa IFX networks, uno de los principales proveedores de servicios de infraestructura de la región. IFX cuenta con cerca de 4200 clientes a nivel regional, tanto empresas privadas como servicios públicos en varios países de la región. Uno de ellos es el Portal de Compras Públicas de Chile – Chilecompra, IFX le suministra servicios de datacenter, que le fueron adjudicados en licitación pública ID 897096-2-LR1.
La falla, se habría producido (según informaciones de prensa) debido a la falta de actualización de algunos de los productos de software que utiliza IFX para dar sus servicios.
Hasta ahora, en que escribo este post (21-9-2023) el sitio web de IFX sigue sin poder levantar yse ve como la siguiente imagen.
Creo que una cosa relevante de este tipo de situaciones es identificar los aprendizajes que la experiencia pueda acarrear, con el objetivo de mejorar los protocolos y formas de operar.
Lo que aprendimos
O más bien, debiera decir estamos aprendiendo, ya que la contingencia aún no ha terminado y no va a faltar la oportunidad de identificar mejoras que pueden preparar a las instituciones para eventos similares, sobre todo cuando estamos hablando de servicios de misión crítica. Aquí expongo algunas de las cosas que he podido identificar como aprendizajes, de seguro hay muchas más.
Selección de Proveedor
Hoy por hoy, la selección de proveedores de servicios de infraestructura TI, debe realizarse cuidadosamente, e identificando las prácticas de gestión de su operación, no basta con las certificaciones que exhiban, ya que el incremento en los ataques últimos años ha sido exponencial y por lo tanto, no sólo las componentes de infraestructura tecnológica son relevantes, sino también protocolos y mecanismos de seguridad son extremadamente relevantes, y lo serán cada vez más. Estas dimensiones se están transformando en elementos esenciales a la hora de evaluar este tipo de proveedores.
En junio de 2019, IFX Networks había obtenido su certificación Tier III, estándar industrial otorgado por el Uptime Institute a los datacenters. El nivel III (Tier III), denominado de mantenimiento simultáneo, esto es, que todos y cada uno de los componentes pueden retirarse de forma planificada para su mantenimiento o sustitución sin que ello afecte a las operaciones. Este nivel plantea un uptime de 99.982% o superior, lo que significa no más de 1.6 horas/año de no servicio. Hasta ahora IFX lleva más de 200 horas horas sin servicio, muy por sobre el compromiso de servicio Tier III ya lleva este año un nivel de uptime de 97,5% y en la medida que esta situación se mantenga el uptime seguirá bajando.
El problema de estas certificaciones es que se centran fundamentalmente en la infraestructura, y bastante menos en la operación, área muy relevante hoy por hoy, dado los problemas de ciberseguridad que afectan a este tipo de servicio, origen del problema ocurrido en este caso.
Otro elemento de la evaluación debe ser el análisis del DRP (Disaster Recovery Plan) o plan de recuperación de desastres que el proveedor tenga.
Gestión de la contingencia
Cuándo nos vemos enfrentados a una contingencia, la decisión de activación de la emergencia debe establecerse en forma rápida, sin titubeos y con métricas de operación claras. Esto lo digo porque muchas veces se pierde tiempo esperando (con la vaga esperanza) que las cosas vuelvan a la normalidad y no tener que entrar en operación de contingencia.
Una buena referencia de un marco metdológico para la continuidad de negocios para el sector público es el desarrollado por el Instituto de Estándares y Tecnologías de los Estados Unidos – NIST.
Toda operación de contingencia debe tener establecido ex-ante algunas métricas mínimas de operación. Algunas de ellas son:
- RTO: tiempo objetivo de recuperación (Recovery time objective), esto es, el tiempo definido para recuperar los servicios luego de un desastre.
- RPO: Punto objetivo de recuperación, es la duración máxima permitida a partir de la cual se pueden restaurar los datos (tolerancia de pérdida de datos).
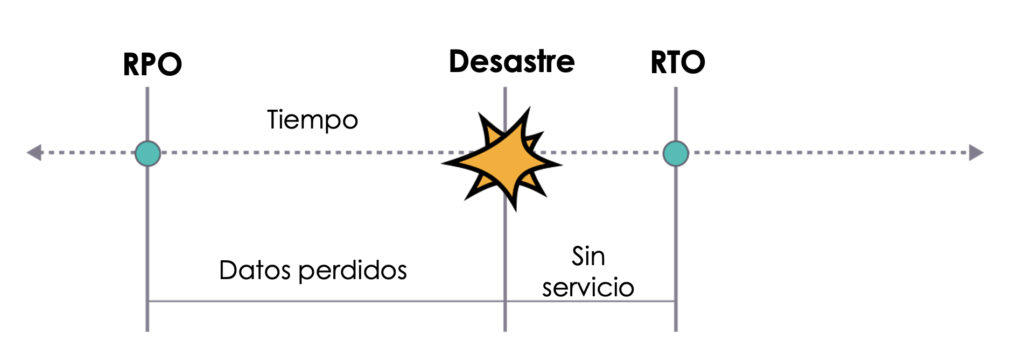
- SLA: Los niveles de servicio a los que se puede aspirar en contingencia, en general nunca (rara vez) se puede llegar a los mismos niveles de servicio que cuando nos encontramos en normalidad. Pero esto se olvida habitualmente.
Con todo esto, se debe establecer una promesa clara del nivel de servicio, utilizando estas métricas, y que sean conocidas por todos los principales stakeholders, de forma que puedan regular expectativas y ajustar sus procesos al modo de contingencia.
Operación en normalidad
La operación en normalidad debe incluir pruebas exhaustivas y recurrentes de activación del DRP, identificar los puntos de falla y realizar en forma permanente BIA’s (Business Impact Analysis) que muestren los riesgos y establecer medidas de mitigación.
No basta con tener procedimientos de respaldo, esto debe ser probados, lo relevante al momento de una contingencia es tener claridad del RTO y el RPO que son aceptables, además del nivel de servicios que puedo dar con una contingencia activada.
Gestión de comunicaciones
Otro elemento clave en estas situaciones, es la estrategia comunicacional que se va a utilizar: ¿qué y cómo comunicar?
Un error frecuente, es salir a buscar un culpable como primera medida, lo hemos visto en el pasado en otros servicios similares. En este caso fue culpar al proveedor de infraestructura, lo cual no es lo más adecuado, ya que para el usuario final eso no le sirve de absolutamente nada, no tuvo ninguna injerencia en su selección y menos aún en su operación. Además que finalmente el problema es del servicio del portal de compras públicos como un todo (experiencia usuaria) y no de uno de sus proveedores.
Otro error, es asociado a las prioridades de las medidas, la Dirección de Compras anunció como primera medida “Medidas legales en contra de proveedor IFX Networks”, si bien es un tema importante, este tipo de medidas son internas, y tiene poco impacto/beneficio al usuario final.

Conclusión
Espero que esta situación se subsane lo antes posible, y que la experiencia vivida sirva para mejorar los procesos y protocolos de contingencia de un servicio tan crítico como el Chilecompra, estableciendo un DRP que contemple nuevos escenarios de contingencia como el que tuvo que vivir el Chilecompra y explorar nuevas formas de gestionar crisis de gran complejidad a las que nos veremos enfrentados de forma más frecuente a futuro.
Por otra parte, esta experiencia puede ser usada como insumo y antecedente para el diseño de la nueva plataforma, que está abordando el Chilecompra, por ejemplo, tomando medidas para una arquitectura más modular y resiliente.
Foto de Alvaro Reyes en Unsplash


Agregaría una variable que es relevante al proceso, normalmente se deja de lado, es el permanente entrenamiento a las personas (técnicas y usuarias) respecto de la relevancia de este tema. Tanto en el uso como en la reacción ante el incidente.
Totalmente de acuerdo Francisco, es un tema clave en procesos como este
Me gustó tu aproximación y vision global del tema.
Yo agregaría que aquí también hay responsabilidades compartidas, si bien es cierto, existen SLA y una calidad de servicio requerida por Chilecompras y comprometida por el proveedor, creo que los clientes deben empoderarse más para poder exigir más, si no tienen los recursos internos que auditen y controlen al proveedor, al menos deberían dejar presupuesto para realizar revisiones periódicas con un tercero.
Hoy en día no hay ningún proveedor de servicios que este ajeno a recibir posibles ataques.
Ojo que tier3 tiene distintos grados de certificación. puedes certificarte en tier3 en diseño, o en construcción, o en Operación. tener tier3 en construcción ( caso ifx ) significa que por motivos de energía, climatización, o conectividad, podrías tener poco mas de una hora de downtime. Pero no tienen certificación de operación ( y en Chile pocos la tienen , lamentablemente )
Así es, IFX tiene las certificaciones Tier III para: Tier III Certification of Design Documents y Tier III Certification of Constructed Facility
Muchas gracias Francisco, efectivamente un elemento clave es la auditoría y pruebas del proveedor, no tengo antecedentes respecto de si estaban contempladas esas pruebas y auditorías
Simple y clara aproximacion quisiera aportar algunos puntos:
Dentro del Plan de Recuperación ante Desastres, debe quedar establecida la estructura organizacional, procesos y responsabilidades en la activación del mismo, asi como también los tiempos «sin servicio» que ameritan la activación del plan. Entre las ya mencionadas, y por cierto que es relevante probar el plan y medir su efectividad y tiempos, verificar si se cumplen los RPO y RTO comprometidos… etc.
Bastante pedagógica y ajustada a la literatura la explicación, pero en la práctica, no solo para el caso de chilecompra sino que en general, es bueno hacer ver qué la responsabilidad de un DRP no es solo del proveedor, también es actor fundamental el contratante, identificando los factores relevantes, midiendo si realmente puede satisfacer las necesidades de RTO y RPO, es decir si daremos una opinión técnica que sea completa y no antojadiza. Siendo sincero leí hasta la primera línea de la gestión de la comunicación, me esperaba más profundidad respecto a cómo activar un DRP pero me pareció que se enfilaba más a una opinión «política», en fin, éxito.