
Inteligencia Artificial, cuidado con los sesgos!

Ahora que estamos en proceso de definir nuestras políticas públicas respecto de la IA, es bueno tener presente sus impactos éticos asociados a privacidad y sesgos!
Esto de los sesgos no es algo nuevo, desde titulares mañosos de los medios de comunicación, algunos llegando a ser francamente burdos; hasta cosas que parecen menores, como el típico mensaje del grupo de WhatsApp familiar que envió algún pariente; pero cuando vemos el efecto que producen las Redes Sociales, fundamentalmente en su efecto de expansión, el poder visualizar los sesgos con mirada crítica se torna algo relevante al día de hoy.
Incluso algunos que tratan de pasar desapercibidos, como hemos visto con gráficos y estadísticas presentadas en forma mañosa en las redes sociales, uno de estos casos me llevó a un largo debate por twitter hace unos días, producto de un gráfico que un economista de la plaza posteó.
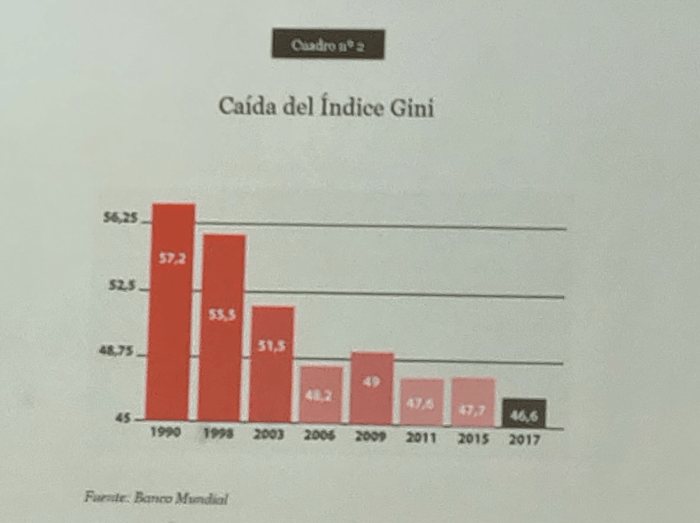
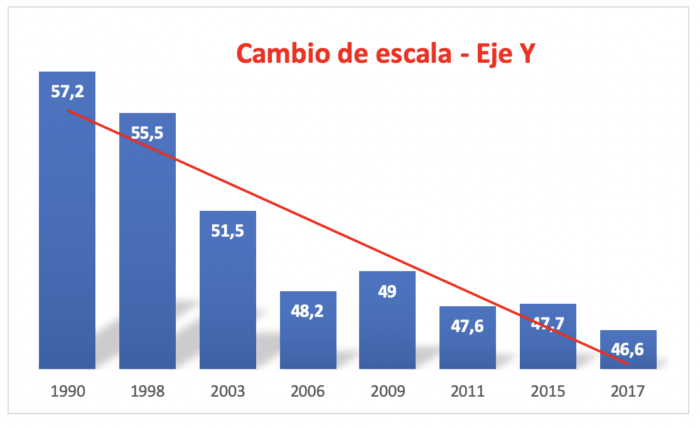
Luego de su posteo, escribí una crítica respecto del problema de sesgo que introduce el gráfico. Recibí varias respuestas, preguntado que tenía de malo el gráfico, si matemáticamente estaba correcto, lo cual es cierto, pero algo que olvida esa persona es que la percepción de tendencia a la baja cambiando la escala del eje Y es diferente. Si lo vemos usando los mismos datos del gráfico anterior, con y sin cambiar la escala del eje Y, percepción respecto de la tendencia (linea roja) es muy diferente en los dos ejemplos que se muestran a continuación. En primer lugar usando la misma escala del gráfico del economista, y luego una escala partiendo de 0.
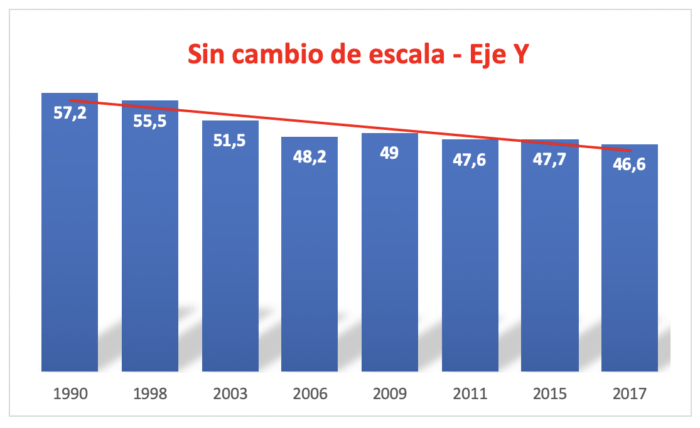
y este otro, usando el eje completo (partiendo desde 0 y no desde 45)
A propósito de este tema, en los últimos días leí el muy buen libro The Ethical Algorithm, recomendación de Ricardo Baeza (gracias Ricardo!) . En el libro dedicado a los desafíos que se nos presentan por delante en materias de Inteligencia Artificial y como hacemos un abordaje ético de ellos, se plantea que existen dos desafíos básicos a la hora de desarrollar algoritmos que nos ayudarán a tomar decisiones en diferentes ámbitos, tales como: carteras de inversiones, evaluación de riesgo en créditos, predicción del desarrollo de una epidemia, asignar beneficios de algún tipo a solicitantes, evaluación de candidatos a un trabajo, predecir riesgo de reincidencia delictual de personas y muchos otros.
Aquí pueden ver un pequeño spoiler del libro:

Al cargar el vídeo, acepta la política de privacidad de YouTube.
Más información
Recordemos que los procesos de Inteligencia Artificial están sustentados en el procesamiento de grandes volúmenes de datos, para a partir de allí establecer modelos predictivos y generar inferencias, y por lo tanto lograr predicciones que permitan tomar mejores decisiones en diferentes ámbitos.
El libro parte señalando que existen dos dimensiones que los algoritmos deben tener en consideración, y que tienen un sustrato de carácter ético.
- Privacidad: uno de los elementos que plantean sus autores es que para poder producir resultados adecuados se requieren de grandes volúmenes de datos, que permitan refinar los modelos y sus resultados, pero aquí nos encontramos con el primer desafío de carácter ético, como conciliar la precisión del modelo con un adecuado uso de datos, que en muchas ocasiones se trata de datos sensibles de las personas. El libro demuestra con bastante detalle y ejemplos cómo los métodos tradicionales de anonimización de datos, no son muy útiles a la hora de proteger la información sensible. Para ello muestra varios ejemplos de como diferentes técnicas permiten “desanonimizar bases de datos”: i) en 1997 se identificó el registro médico del gobernador del estado de Massachusetts en Estados Unidos, usando para ello la relación entre varias bases de datos de registros públicos, ii) el segundo ejemplo es lo que le ocurrió a la empresa Netflix cuando liberó una base de de 500.000 usuarios para el desarrollo de un concurso público que buscaba mejorar su sistema de recomendaciones, un estudio demostró que usando la base de datos de películas IMDB se podía desanonimizar la base de datos liberada por Netflix. La forma de resolver este desafío según los autores es utilizado el concepto de privacidad diferencial, la cual se logra por la vía de introducir ruido en los datos, y que de esta forma se logre garantizar la privacidad, esta técnica ya está siendo adoptada por muchas instituciones y empresas, probablemente el ejemplo más emblemático de esto es la oficina de Censos de los Estado Unidos para su censo 2020.
- Justicia: otro desafío significativo a la hora de desarrollar algoritmos es que estos se comporten de forma “justa”, esto es, sin introducir sesgos o al menos teniendo claridad de la existencia de estos e intentando reducirlos al máximo. Estos sesgos ya los hemos visto en diferentes ámbitos, por ejemplo, en los algoritmos de reconocimiento facial que tienen sesgos raciales, o bien los algoritmos de asociación de conceptos en los cuales se ha demostrado el sesgo de género. Para ello, los autores plantean el uso del concepto de la Frontera de Pareto ya que los procesos de machine learning, tienen una relación directa entre justicia (sesgo) y nivel de error del modelo. Esto permite que se puedan tomar decisiones frente a ambas dimensiones, y poder sensibilizar el modelo, en función de esos criterios. El gráfico siguiente, proveniente del libro, muestra esa frontera y la relación entre justicia y nivel de error
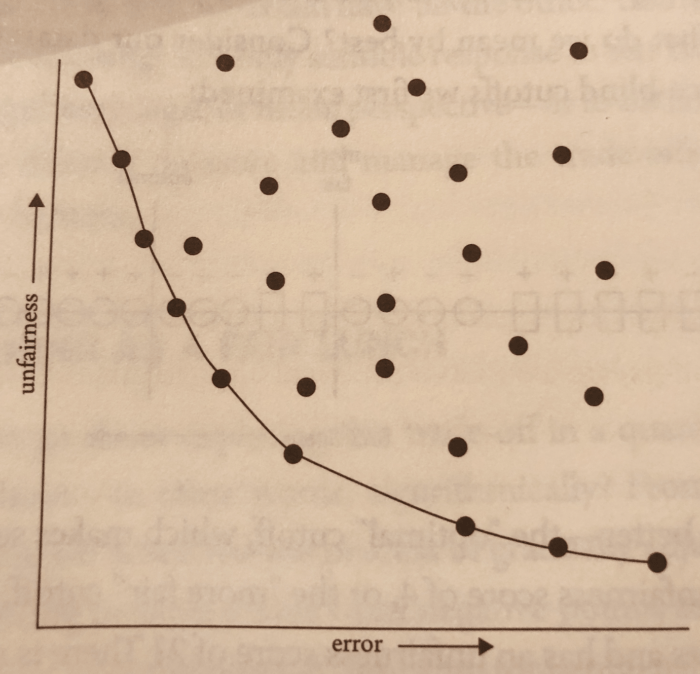
Hoy en día, que los países están abordando la problemática y regulación en torno a la Inteligencia Artificial, creo que estas dimensiones tienen que ser centrales a la hora de discutir y definir esas políticas públicas.
Photo by Markus Spiske from Pexels


Muy buen articulo Alejandro, sobre todo para quienes trabajamos en el estado gestionando grandes volúmenes de información con datos sensibles.
Gracias Alejandro, muy útil. Podría abogarse para que ciertos algoritmos sean públicos y uno poder tomar conciencia de los sesgos (a veces parecen cajas negras) Creo que tenemos derecho a saber como están diseñados en ciertas ocasiones.
Gracias Alejandro
muy interesante tema. La etica en uso de los datos y ajuste de los algoritmos es clave. Lamentable la postura del ecobomista en distorsionar la presentación de una información tan sensible como la distribución del ingreso.
Gracias, Alejandro.
Agrego links sobre el debate sobre el tema:
Y en Chile, el Ministerio de Ciencia, Tecnología, Conocimiento e Innovación realizará seminarios sobre IA en todas las regiones desde este mes hasta junio. Alimentará así el documento base que una comisión de expertos (http://bit.ly/2ThpWcf) elaborará durante 2020.
Uno puede participar; incluso, enviar reflexiones por mail (http://bit.ly/32tAXv7). Se acordará una política de IA para Chile.
Muchas gracias Nicolás por el comentario y los links
Gracias Victoria por el comentario, efectivamente yo creo que el tema d hacer públicos ciertos algoritmos es esencial y veo poco eso en el debate
Gracias Octavio por el comentario